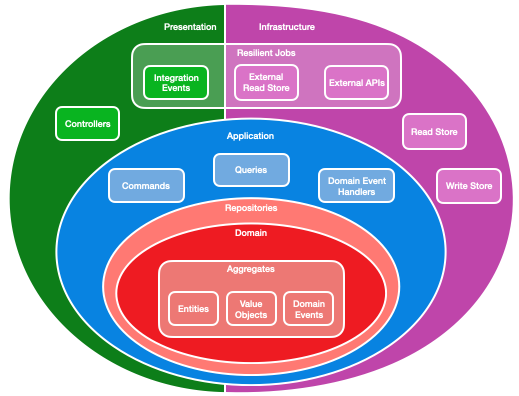
Onion Architecture with DDD and CQRS
A lot of software engineering is about drawing boxes. That is, deciding how to break down the code we write. We don’t just write everything in the Main method. We set boundaries, create abstractions, and divide things into single responsibilities.
In C#, we group code into methods. Then we group those into classes and decide that some methods are private. We do the same again, grouping classes into libraries, and then the same again within a whole solution. At each level we decide what is internal and what becomes our public contracts.
Once we’ve split everything up into boxes, we stitch it all back together again with some arrows. Libraries reference other libraries, classes depend on other classes, and methods call other methods. But it’s not meaningless. The arrows represent a direction of dependency, where a box “knows of” the other box it is pointing to. At least, it knows the public contracts, not the internals.
Direction is one-way. We should ensure boxes don’t know of each other, otherwise we will create a circular dependency and tightly couple those boxes together.

Inverting Project Dependency
Many developers will be familiar with the N-Tier project architecture. Usually 3 layers: presentation, business logic and data access. We say the data access layer doesn’t know of the business logic that calls it; it just puts things in a database. Similarly, the business logic doesn’t know of the API. In this architecture, the direction of dependency goes in the same direction as the flow of control, which is the direction method calls are made. You can think of control as calling or driving. It’s which code tells which what to do and when to do it.
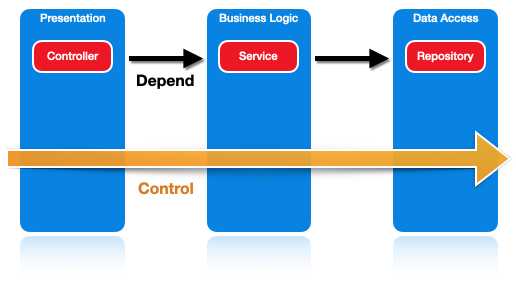
These arrows do not have to point in the same direction. For example, if a Service class in the business logic layer knows of an IRepository interface, and the Repository implementation also knows of the IRepository interface, all we need to do is move the interface to the business logic layer, and suddenly the data access must reference the business logic instead. We’ve inverted the project dependency.
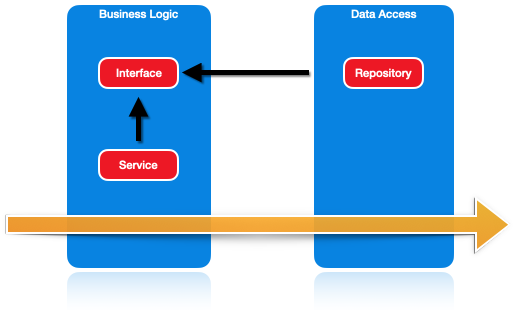
Ports and Adapters
This is the fundamental principle behind the Ports and Adapters architecture. By inverting that project dependency, the business logic has no dependencies. There aren’t even transitive dependencies to libraries like EntityFramework this way, so we can’t accidentally use them in the business logic layer. It becomes easily testable, as there are no databases, no HTTP requests; it’s pure C# code.
Instead, the business logic defines the IRepository and the entity objects as a public contract called a port. It says:
Here is a port that I know how to use. Please, someone implement this port.
Other projects can implement the interfaces by creating adapters. We could create an EntityFrameworkRepository that implements our business logic’s port and wraps up Entity Framework’s DbSet. This is the Adapter pattern.
public class EntityFrameworkRepository : IRepository
{
private readonly DbSet<MyObject> _dbSet;
public EntityFrameworkRepository(DbContext dbContext)
{
_dbSet = dbContext.MyTable;
}
public void Add(MyObject obj)
{
_dbSet.Add(obj);
}
// ... other repository methods
}
Hexagonal Architecture
Ports and Adapters was originally called the Hexagonal Architecture. There is nothing special about the number six here. It’s just a nice way to visualise the architecture. It’s diagrams tend to use a hexagon in the middle, but the shape doesn’t matter; it can just as easily be drawn as a circle.
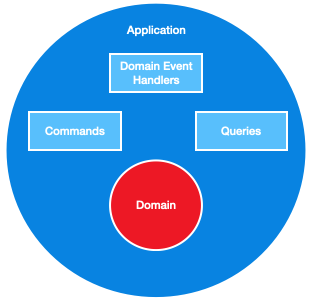
Onion Architecture is just Ports and Adapters architecture, but the business logic is further divided into more layers. We draw the layers as circles around each other and the direction of dependency goes inwards.
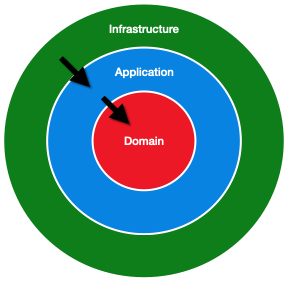
Now, let’s build up that architecture, starting with the middle and working our way outwards.
The Domain Layer with DDD
At the heart of our application is a single project with no dependencies. For this, we will use Domain-Driven Design. This is not a requirement of Onion Architecture, but it is a convenient way to divide our logic.
Before introducing the building blocks of DDD, it’s important to mention that DDD is not fundamentally about the technical detail, but is focused around the domain model and how the language and structure of the code should match the business domain. It’s a collaboration between technical and domain experts.
A great way to develop this language is Event Storming, where the domain experts tell a story of what happens in their domain. Throughout the story they will describe events that are of interest to them, which we model as Domain Events.
Domain Events are written in past tense, such as AccountRegistered or PaymentTaken, because they have already happened at the time we initialise them. Once they’re initialised, the objects are immutable; you cannot go back and change the past.
When an event is raised, the domain doesn’t know who’s listening. It calls out to anyone who has subscribed to the event in advanced, but it doesn’t know who. The control flows out of the domain to an event handler, but it is the handler that knows of the event. Again, we have inverted the dependency. Like Ports and Adapters, raising events is another technique that allows the control to flow in the opposite direction to the project reference.
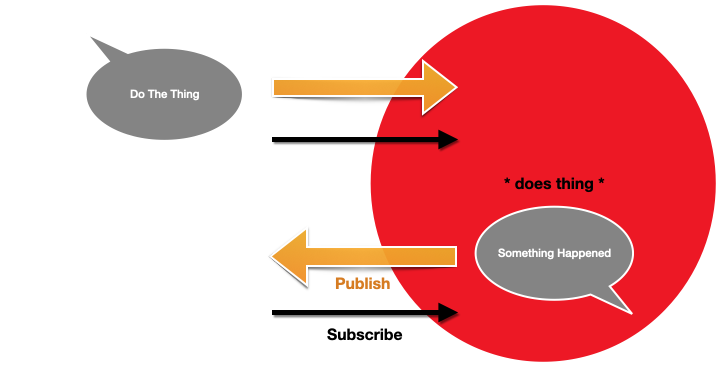
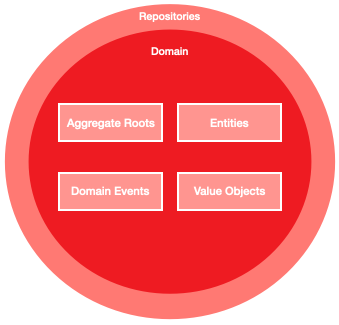
Events usually represent a change to the state of a domain entity. Entities and other domain objects are grouped together into clusters called aggregates, which provide a consistency boundary and can enforce the business rules of the domain.
Aggregates are stored in repositories, which are abstractions for data storage. They are ports that the domain defines and expects to be implemented in the outer layers.
And finally, the unit of work is another abstraction, this time for a data transaction. All the work done, all the changes made to aggregates and repositories, are committed together as one unit.
I like to think of the data abstractions as sitting in a thin layer just on the edge of the domain layer. In Onion Architecture, dependencies go inwards, so my repositories know of my aggregates, but not the other way round.
The Application Layer with CQRS
We’re going to build the layer just outside of the domain layer using Command Query Responsibility Segregation. This means our application layer will be made up of two sub-systems: a command side, responsible for executing tasks and making changes to our domain; and a query side, responsible only for getting data.
Both sides will be entirely separated from each other. They won’t share any models or classes. This is essentially the opposite of CRUD. I found this difficult to grasp at first, because I was designing RESTful APIs as the front-end. I instinctively thought of writing a certain resource to a location, and then getting that same shape back out of that location, which is breaking the only rule of CQRS; separate the read and write concerns.
The Command Side
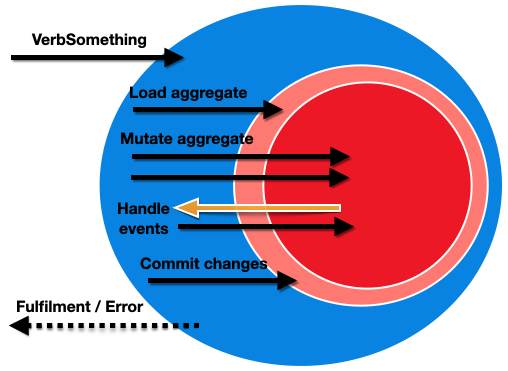
For commands, think task-based, rather than resource-based. What are we actually trying to do? Once we’ve worked out what the command looks like, that becomes the public contract for our application layer. The command is sent into this layer and handled by a CommandHandler, which is responsible for:
- Creating or loading an aggregate from a
Repository - Calling methods on that aggregate to make changes.
- Committing the
IUnitOfWork.
public class OpenTinCommandHandler : ICommandHandler<OpenTinCommand>
{
private readonly ITinRepository _tinRepository;
private readonly IUnitOfWork _unitOfWork;
public OpenTinCommandHandler(ITinRepository repository, IUnitOfWork unitOfWork)
{
_repository = repository;
_unitOfWork = unitOfWork;
}
public async Task Handle(OpenTinCommand command)
{
var tin = await _repository.Get(command.TinId);
tin.Open();
await _unitOfWork.Commit();
}
}
Note that this command returns only a Task. We’re not going to return any business data. Certainly not our read models.
However, we could throw an exception here. We can return data about the command execution itself. We might prefer to return a custom CommandResult object with error information included. But definitely not any business data; that is what queries are for.
A command either succeeds or it doesn’t. It cannot return that half of the command worked. If multiple changes are made on an aggregate, or if domain events raised by the changes are handled and make further changes, everything must be committed as one unit of work.
public async Task Handle(OpenTinCommand command)
{
var tin = await _repository.Get(command.TinId);
tin.PickUp();
tin.Open();
tin.PutDown();
await _unitOfWork.Commit();
}
I like to view the whole application layer as this transaction boundary. From outside, we don’t worry about the transaction, we just send a command, and it either succeeds or fails.
The Query Side
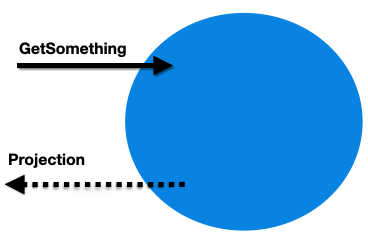
The other half of our application will handle reads. Think about what information we need to know, then we can directly return that ViewModel.
Query objects look very similar to Commands, and are handled similarly with a QueryHandler class.
However, in this side, we don’t want to use our repositories, aggregates or entities; they are our write models. We certainly don’t want to be returning them from our queries, because consumers could use them to make changes to the system. Instead, we just project our query results straight onto the response object.
public class GetBreakfastQueryHandler : IQueryHandler<GetBreakfastQuery>
{
private readonly IBreakfastQueryable _queryable;
public GetBreakfastQueryHandler(IBreakfastQueryable queryable)
{
_queryable = queryable;
}
public async Task<Breakfast> Handle(GetBreakfastQuery query)
{
var ingredients = await _queryable
.Where(i => i.IsVegetarian == query.IsVegetarian)
.Select();
return new Breakfast(ingredients);
}
}
We have the freedom to do powerful things here. We could execute queries that join several tables together. We could use a different database technology from our write side, like Dapper. We could even read from a totally different database, called a read store.
CQRS gives us the power to scale the two concerns independently. We can optimise a query that uses joins by moving to use a denormalised table designed for the query instead. The table can be sourced by handling events, so that the query results are calculated when the command is executed, instead of on-the-fly every time.
Jobs and Resiliency
Writing to the read store can be done as part of the same database transaction to ensure consistency between the read and write sides. This is done by making changes to another table in a DomainEventHandler, which is handled within the same UnitOfWork as the command execution.
public class TinOpenedDomainEventHandler : IDomainEventHandler<TinOpenedEvent>
{
private readonly IStatsCollection _statsCollection;
public TinOpenedDomainEventHandler(IStatsCollection statsCollection)
{
_statsCollection = statsCollection;
}
public async Task Handle(TinOpenedEvent domainEvent)
{
_statsCollection.Add(new OpenedTinsStat
{
FoodType = domainEvent.FoodType,
Cost = domainEvent.CostOfTin
});
}
}
This isn’t possible with a totally different database. Instead, we must schedule a job to write the changes after the transaction has committed. The scheduling itself must be done within the transaction, so I like to view this as just writing to another read store (the jobs store) which is later queried by a job processor. When the job is executed, the changes have already been made, so we cannot throw an error when processing the job. The job must therefore be processed with a retry mechanism to ensure it completes.
public async Task Handle(TinOpenedEvent domainEvent)
{
if(_tinFinder.GetTinCount(domainEvent.FoodType) < 20)
{
_jobs.Schedule(new BuyMoreTinsJob
{
FoodType = domainEvent.FoodType
});
}
}
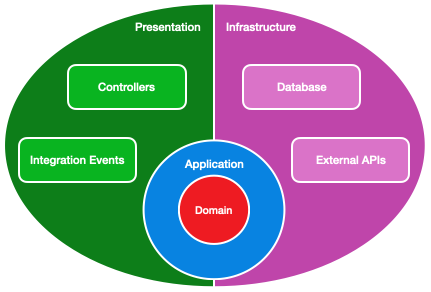
The Infrastructure Layer
The outermost layer integrates our application with the outside world, such as networks, databases or a message bus. We’d most likely see a persistence project here, responsible for implementing our IRepository interfaces.
Being the layer that can communicate outside our application, we’d expect to see projects that understand external APIs. Calls will often be driven by the application. For example, a project responsible for making calls to PayPal might implement an adapter for an IMoneySender port.
The Presentation Layer
The infrastructure is sometimes divided into two. One half is our presentation layer, which will send our commands and queries into our application.
Sometimes this split is divided by the flow of control, with driving adapters on one side and driven adapters on another. Often these layers are thought of as csproj projects, which would mean our API calls the application layer, which in turn calls the external APIs. This is not always the case. An external API may provide WebHooks that call back into the infrastructure layer. Similarly, our own API may have some push functionality, such as WebHooks or SignalR.
Instead, I like to think of the presentation layer as containing my public contracts, whether the control flows in or out. This means integration events belong on this side of my diagram; they are documented alongside my API and are part of what I present to the world outside of the service.
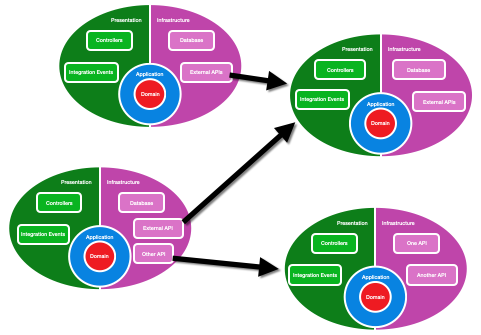
In a microservices architecture, the external API libraries may reference another micro-service. We still want to avoid circular dependencies at this higher level, so this gives our whole system architecture a flow of dependency, with core services on the right hand side of our diagram.
TL;DR
I call controllers in the presentation layer, which send commands to my application layer, which load aggregates from the domain layer, using repositories which are implemented in the infrastructure layer as an adapter to the write store.
Aggregates are made up of entities and value objects. They handle all changes and raise domain events, which are handled in the application layer, either by making further changes to aggregates, or by writing to a read store, which can later be queried by controllers or resilient jobs, such as publishing integration events, writing to an external read store, or calling external APIs.